Unidad 3 Pruebas de hipótesis
3.1 Concepto
Una hipótesis estadística o simplemente hipótesis es una pretensión o aseveración sobre el valor de un solo parámetro (característica de la población o característica de una distribución de la población) o sobre los valores de varios parámetros (Devore, 2008, página 285) (Anderson et al., 2008, página 340).
En cualquier cualquier problema de prueba de hipótesis, existen dos hipótesis contradictorias consideradas, la hipótesis nula y la alternativa.
La hipótesis nula denotada por \(H_0\), es la pretensión de que inicialmente se supone cierta (la pretensión de “creencia previa”). La hipótesis alternativa denotada por \(H_1\) (o \(H_a\)), es la aseveración contradictoria a \(H_0\).
La hipótesis nula será rechazada en favor de la hipótesis alternativa solo si la evidencia muestral sugiere que \(H_0\) es falsa. Si la muestra no contradice fuertemente a \(H_0\), se continuará creyendo en la verdad de la hipótesis nula. Las dos posibles conclusiones derivadas de un análisis de prueba de hipótesis son entonces rechazar \(H_0\) o no rechazar \(H_0\).
3.1.1 Elaboración
En algunas aplicaciones no parece obvio cómo formular la hipótesis nula y alternativa. Se debe tener cuidado en estructurar la hipótesis apropiadamente de manera que la conclusión de la prueba de hipótesis proporcione la información que el investigador o la persona encargada de tomar las decisiones desea. A partir de la situación, las pruebas de hipótesis pueden tomar tres formas (tabla 3.1), las cuales se diferencian en el desigualdad o igualdad empleada en la hipótesis alternativa.
| Caso 1 | Caso 2 | Caso 3 |
|---|---|---|
| \(H_0: \theta = \theta_0\) | \(H_0: \theta = \theta_0\) | \(H_0: \theta = \theta_0\) |
| \(H_1: \theta \neq \theta_0\) | \(H_1: \theta > \theta_0\) | \(H_1:\theta < \theta_0\) |
En diversas ocasiones, \(H_1\) se conoce como la “hipótesis del investigador”, puesto que es la pretensión que al investigador en realidad le gustaría validar. La palabra nulo “significa sin valor”, lo que sugiere que \(H_0\) es identificada como la hipótesis de ningún cambio.
Ejemplo 3.1 Considérese, que el 10% de todas las tarjetas de circuito producidas por un cierto fabricante durante un periodo de tiempo reciente estaban defectuosas. Un ingeniero ha sugerido un cambio en el proceso de producción en la creencia de que dará por resultado una proporción reducida del proceso cambiado.
La hipótesis alternativa (posición del investigador) es \(H_1: p <0.10\), la pretensión de que la modificación del procesos redujo la proporción de las tarjetas defectuosas. Una opción natural para \(H_0\) en esta situación es la pretensión contraria a la establecida en \(H_1\), es decir, \(p\geq 0.1\). En su lugar se considera \(H_0: p = 0.1\) contra \(H_1: p < 0.1\), tal como se expuso en la tabla anterior.
Ejercicio 3.1 El gerente de Danvers-Hilton Resort afirma que la cantidad media que gastan los huéspedes en un fin de semana es menos de \(\$600\) dólares. Un miembro del equipo de contadores observó que en los últimos meses habían aumentado tales cantidades. El contador emplea una muestra de cuentas de fin de semana para probar la afirmación del gerente.
- ¿Qué forma de hipótesis deberá usar para probar la afirmación del gerente? Explique.
Caso 1 Caso 2 Caso 3 \(H_0: \mu = 600\) \(H_0: \mu = 600\) \(H_0: \mu = 600\) \(H_1: \mu \neq 600\) \(H_1: \mu > 600\) \(H_1:\mu < 600\) - ¿Cuál es la conclusión apropiada cuando no se puede rechazar la hipótesis nula \(H_0\)?
- ¿Cuál es la conclusión apropiada cuando se puede rechazar la hipótesis nula \(H_0\)?
Ejercicio 3.2 El gerente de un negocio de venta de automóviles está pensando en un nuevo plan de bonificaciones, con objeto de incrementar el volumen de ventas. Al presente, el volumen medio de ventas es 14 automóviles por mes. El gerente desea realizar un estudio para ver si el plan de bonificaciones incrementa el volumen de ventas. Para recolectar los datos, una muestra de vendedores venderá durante un mes bajo el nuevo plan de bonificaciones.
- Dé las hipótesis nula y alternativa más adecuadas para este estudio.
- Comente la conclusión resultante en el caso en que \(H_0\) no pueda rechazarse.
- Comente la conclusión que se obtendrá si \(H_0\) puede rechazarse.
Ejercicio 3.3 Debido a los costos y al tiempo de adaptación de la producción, un director de fabricación antes de implantar un nuevo método de fabricación, debe convencer al gerente de que ese nuevo método de fabricación reducirá los costos. El costo medio del actual método de producción es \(\$220\) por hora. En un estudio se medirá el costo del nuevo método durante un periodo muestral de producción,
- Dé las hipótesis nula y alternativa más adecuadas para este estudio.
- Haga un comentario sobre la conclusión cuando \(H_0\) no pueda rechazarse.
- Dé un comentario sobre la conclusión cuando \(H_0\) pueda rechazarse.
3.1.2 Errores tipo I y II
Las hipótesis nula y alternativa son afirmaciones opuestas acerca de la población. Una de las dos, ya sea la hipótesis nula o la alternativa es verdadera, pero no ambas. Lo ideal es que la prueba de hipótesis lleve a la aceptación de \(H_0\) cuando \(H_0\) sea verdadera y al rechazo de \(H_0\) cuando \(H_1\) sea verdadera. Por desgracia, las conclusiones correctas no siempre son posibles. Como la prueba de hipótesis se basa en una información muestral debe tenerse en cuenta que existe la posibilidad de error.
Los dos tipos de errores que se pueden cometer son:
- Error tipo I: Rechazar \(H_0\) cuando \(H_0\) es verdadera.
- Error tipo II: No rechazar \(H_0\) cuando \(H_0\) es falsa.
Es posible el error que se desea cometer, es decir, es posible establecer la probabilidad de cometer un error tipo I o II, pero no ambos. El nivel de significancia es la probabilidad de cometer un error tipo I cuando la hipótesis nula es verdadera. Para denotar el nivel de significancia se usa la letra griega \(\alpha\), y los valores que se suelen usar para \(\alpha\) con 0.05 y 0.01.
Ejemplo 3.2 Walter Williams, columnista y profesor de economía en la universidad George Mason indica que siempre existe la posibilidad de cometer un error tipo I o un error tipo II al tomar una decisión (The Cincinnati Enquirer, 14 de agosto de 2005). Hace notar que la Food and Drug Administration corre el riesgo de cometer estos errores en sus procedimientos para la aprobación de medicamentos.
Cuando comete un error tipo I, la FDA no aprueba un medicamento que es seguro y efectivo. Al cometer un error tipo II, la FDA aprueba un medicamento que presenta efectos secundarios imprevistos. Sin importar la decisión que se tome, la probabilidad de cometer un error costoso no se puede eliminar.
Ejercicio 3.4 Nielsen informó que los hombres jóvenes estadounidenses ven diariamente 56.2 minutos de televisión en las horas de mayor audiencia (The Wall Street Journal Europe, 18 de noviembre de 2003). Un investigador cree que en Alemania, los hombres jóvenes ven más tiempo la televisión en las horas de mayor audiencia. Este investigador toma una muestra de hombres jóvenes alemanes y registra el tiempo que ven televisión en un día. Los resultados muestrales se usan para probar las siguientes hipótesis nula y alternativa.
\[\begin{equation} \notag \begin{split} H_0&: \mu = 56.2\\ H_1&: \mu > 56.2\\ \end{split} \end{equation}\]- En esta situación, ¿cuál es el error tipo I? ¿Qué consecuencia tiene cometer este error?
- En esta situación, ¿cuál es el error tipo II? ¿Qué consecuencia tiene cometer este error?
Ejercicio 3.5 Suponga que se va a implantar un nuevo método de producción si mediante una prueba de hipótesis se confirma la conclusión de que el nuevo método de producción reduce el costo medio de operación por hora.
- Dé las hipótesis nula y alternativa adecuadas si el costo medio de producción actual por hora es \(\$220\).
- En esta situación, ¿cuál es el error tipo I? ¿Qué consecuencia tiene cometer este error?
- En esta situación, ¿cuál es el error tipo II? ¿Qué consecuencia tiene cometer este error?
3.1.3 Procedimiento de prueba
Un procedimiento de prueba es un regla, basada en datos muestrales, para decidir si rechazar \(H_0\). Este proceso consta de dos elementos:
- Estadístico de prueba: Función de los datos muestrales en los cuales ha de basarse la decisión.
- Región de rechazo: Conjunto de todos los valores estadísticos de prueba por los cuales \(H_0\) será rechazada.
Para decidir si \(H_0\) es finalmente rechazada es posible ocupar dos métodos.
- Método del valor p
Un valor-p es una probabilidad que porta a una medida de evidencia suministrada por la muestra contra la hipótesis nula. Valores pequeños indican una evidencia mayor contra la hipótesis nula.
Además de representar un probabilidad, el valor-p puede ser vista como una porción de área bajo la curva. La figura 3.1 muestra la relación entre los distintos elementos ya mencionados.
La curva corresponde a la función de probabilidad de los datos. Los valores centrales son aquellos que son más probables de observar (parte más alta de la curva), mientras que los valores extremos (derecha e izquierda) son los menos probables de observar. El punto de color rojo corresponde al estadístico de prueba, función que nos dará un valor con el que seremos capaces de rechazar o no \(H_0\). Finalmente el área de color verde corresponde al área bajo la curva desde el estadístico observado hacia la izquierda (en este caso).
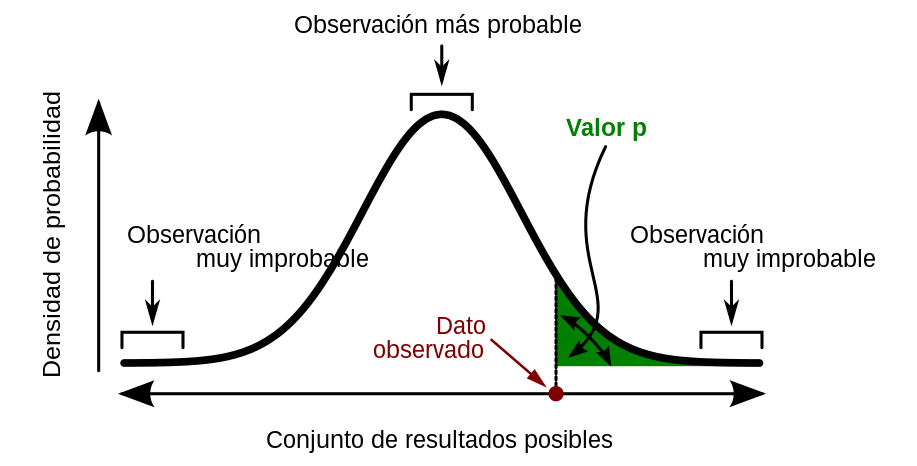
Figura 3.1: Estadístico de prueba para un prueba altenativa con signo \(>\)
La tabla 3.2, da cuenta de la relación que existe entre las pruebas de hipótesis y la ubicación del valor-p en el gráfico presentado.
| Signo de comparación en \(H_1\) | Referencia | Ubicación del estadístico de prueba y valor-p |
|---|---|---|
| \(>\) | Unilateral derecha | A la derecha del gráfico |
| \(<\) | Unilateral izquierda | A la izquierda del gráfico |
| \(\neq\) | Bilateral | A ambos lados del gráfico |
La regla de rechazo usando el valor-p es
\[\text{Rechazar } H_0 \text{ si el valor-p } \leq \alpha\]
En la figura 3.2, se puede observar los tres casos posibles para las distintas hipótesis alternativas, en las cuales se ejemplifica un valor-p en cada uno de los casos. De izquierda a derecha, las hipótesis alternativas correspondientes son unilateral izquierda, unilateral derecha, y bilateral.
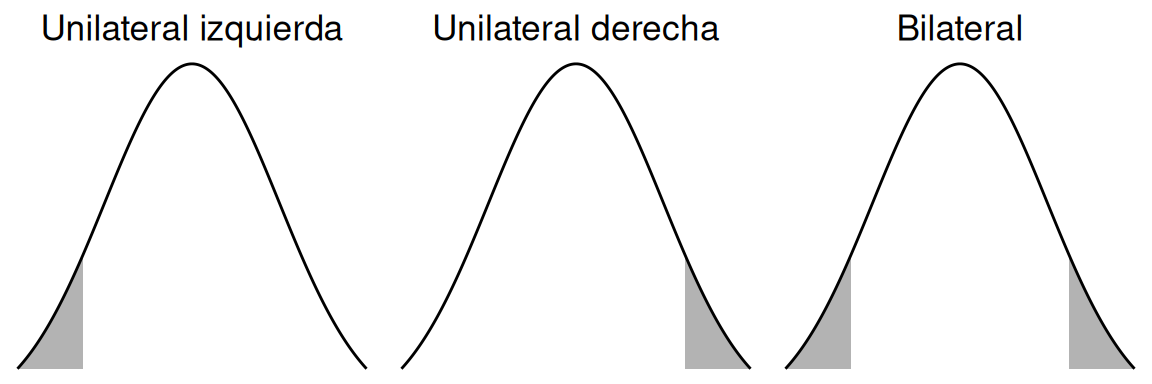
Figura 3.2: Valores -p por tipo de hipótesis alternativa
La decisión de si en cada uno de los casos se rechaza o no la hipótesis nula, depende del valor elegido para la significancia. En la figura 3.3 se muestra la comparativa entre el valor-p y \(\alpha\) para el caso de una hipótesis alternativa unilateral derecha; el área sombreada de color rojo corresponde al valor de \(\alpha\) (área de rechazo), mientras que el área sombreada de color gris corresponde al valor-p definido por el estadístico de prueba.
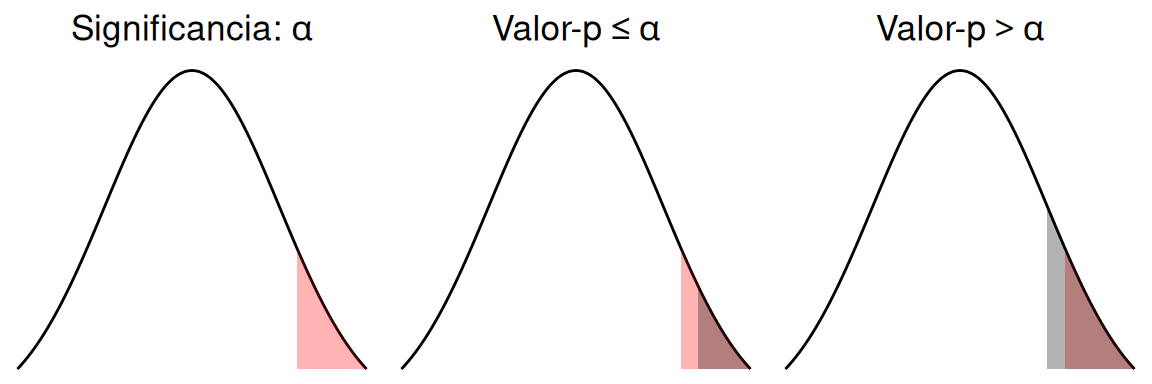
Figura 3.3: Comparativa del valor-p y el área de rechazo para una prueba unilateral derecha
Cabe recordar que, el valor de alfa (valor del área roja en la figura 3.3) estará dado por el investigador (subjetivo), mientras que el valor del área gris se debe determinar a partir de los datos de la muestra (estadístico de prueba).
- Método del valor crítico
Este método consiste en comparar el estadístico de prueba con un número fijo llamado valor crítico. El valor crítico es un punto de referencia para determinar si el valor del estadístico de prueba es lo suficientemente pequeño para rechazar la hipótesis nula. El valor crítico corresponde a la coordenada del eje horizontal que define el área llamada \(\alpha\) (fijado por el investigador), y está ubicada en el mismo sector que el valor-p.
El intervalo de números generado a partir del valor crítico es lo denominado región de rechazo. En la figura 3.4, se observa que una hipótesis nula es rechazada cuando el valor-p es menor o igual a \(\alpha\), lo cual, es equivalente a decir que (gráfico de la izquierda), el estadístico de prueba (1.4) es mayor o igual al valor crítico (0.8), a esto se le denomina “caer en la región de rechazo”. El razonamiento de rechazo utilizando el valor crítico depende de la zona en la que se ubica alfa y el valor-p.
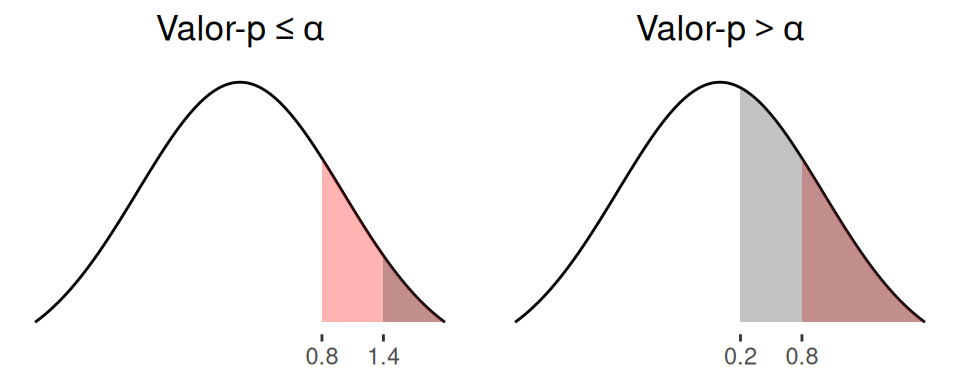
Figura 3.4: Método del valor crítico para una hipótesis unilateral derecha
Los lineamientos de cómo construir un estadístico de prueba, determinar el varlo crítico y el valor-p asociados a una prueba de hipótesis, se darán a conocer a partir de la sección 3.2.
3.1.4 Intervalos de confianza
Existe un relación directa entre las pruebas de hipótesis y los intervalos de confianza, ya que estos pueden ser utilizados para rechazar o no \(H_0\). La tabla 3.3, da cuenta de del tipo de intervalo de confianza que se debe elaborar para cada tipo de prueba de hipótesis.
| Signo de comparación en \(H_1\) | Tipo de intervalo de confianza |
|---|---|
| \(>\) | \((a,\infty )\) |
| \(<\) | \((-\infty ,b)\) |
| \(\neq\) | \((a,b)\) |
A lo largo de las distintas pruebas, se abordarán los distintos métodos de prueba, incluyendo el uso de intervalos de confianza.
3.2 Prueba de hipótesis para una media
Esta sección se centra en el planteamiento y prueba de hipótesis relacionadas a la parámetro de media. Para cada uno de estos casos, se detalla el procedimiento en R y los distintos métodos de prueba para la decisión de rechazo de \(H_0\). En particular, las pruebas para este parámetro requieren que la distribución poblacional de la variable de estudio es normal, lo cual, se asumirá en los enunciados de los ejercicios y/o ejemplos según corresponda.
3.2.1 Varianza poblacional conocida
Aun cuando la suposición de que el valor de \(\sigma^2\) es conocido, rara vez se cumple en la práctica. Este caso proporciona un buen punto de partida debido a la facilidad con que los procedimientos generales y sus propiedades pueden ser desarrollados. La hipótesis nula en los tres casos propondrá que \(\mu\) tiene un valor numérico particular, el valor nulo, el cual será denotado por \(\mu_0\).
El estadístico de prueba y los valores críticos de comparación están dados en la tabla 3.4.
| Hipótesis nula | Estadístico de prueba | Hipótesis alternativa | Criterio de rechazo |
|---|---|---|---|
| \(H_0: \mu = \mu_0\) | \(Z_0 = \displaystyle\frac{\bar{x}-\mu_0}{\sigma/\sqrt{n}}\) | \(H_1: \mu \neq \mu_0\) | \(|Z_0| \geq Z_{1-\alpha/2}\) |
| \(H_1: \mu \gt \mu_0\) | \(Z_0 \geq Z_{1-\alpha}\) | ||
| \(H_1: \mu \lt \mu_0\) | \(Z_0 \leq Z_{\alpha}\) |
Ejemplo 3.3 El índice Rockwell de dureza para acero se determina al presionar una punta de diamante en el acero y medir la profundidad de la penetración, el cual tiene un varianza de medición de 6. Para 50 especímenes de una aleación de acero, el índice Rockwell de dureza promedió 62. El fabricante dice que esta aleación tiene un índice de dureza promedio menor a 64. Asumiendo que el índice de dureza sigue una distribución normal, ¿hay suficiente evidencia para refutar lo dicho por el fabricante con un nivel de significancia de 1%?
Al plantear la prueba de hipótesis se debe tener en cuenta que la hipótesis del investigador ha de estar reflejada en \(H_1\), tal como se muestra a continuación.
- \(\mu\): media del índice de dureza de la aleación de acero.
Método del valor-p
Verificación del criterio de rechazo: Valor-p \(\leq \alpha\).
## [1] -5.773503## [1] 3.882018e-09## [1] TRUEInterpretación utilizando el método del valor-p: El valor-p de 3.88 \(\times 10^{-9}\) es menor o igual a la significancia del 0.01, por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que la media del índice de dureza de la aleación de acero es menor a 64. Considerando una confianza del 99%.
Método del valor crítico
En caso de que deseemos utilizar el método del valor-p, es necesario apoyarnos en R para realizar el calculo de este. El comando necesario para calcular el valor depende la prueba que estemos llevando a cabo, por lo que en el siguiente documento podrán encontrar un resumen para las distintas pruebas.
Verificación del criterio de rechazo: \(Z_0 \leq Z_{\alpha}\).
## [1] -2.326348## [1] TRUEInterpretación utilizando el método del valor crítico: El valor del estadístico de prueba de -5.7735 es menor o igual al valor crítico de -2.3263, por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que la media del índice de dureza de la aleación de acero es menor a 64. Considerando una confianza del 99%.
Método del intervalo de confianza
Al igual que el valor-p, la forma en la que se debe usar el intervalo de confianza varía dependiendo del tipo de prueba de hipótesis que se realiza, por lo que en el siguiente documento podrán encontrar un resumen para las distintas pruebas, dicho documento incluye los distintos comando en R para obtener los resultados de una prueba de hipótesis de manera automática.
Verificación del criterio de rechazo: \(\mu_0 \notin\) IC.
El intervalo de confianza a construir es:
\[\begin{equation} \notag \left(-\infty, \bar{x} + Z_{1-\alpha}\frac{\sigma}{\sqrt{n}}\right) \end{equation}\]# Cálculo de los límites del intervalo de confianza Limite_superior = 62 + qnorm(0.99)*sqrt(6)/sqrt(50) Limite_superior## [1] 62.80587## [1] TRUEInterpretación utilizando el método del intervalo de confianza: El intervalo de confianza \((-\infty, 62.8058)\) no contiene al valor de \(\mu_0 = 64\), por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que la media del índice de dureza de la aleación de acero es menor a 64. Considerando una confianza del 99%.
Para este tipo de pruebas, no hay comandos en R que permitan hacer el trabajo de manera automática. Esto es debido a lo expuesto en un principio: difícilmente se conoce la varianza poblacional en la práctica.
Ejercicio 3.6 Sea el estadístico de prueba \(Z_0\) con una distribución normal estándar cuando \(H_0\) es verdadera. Dé el nivel de significación en cada una de las siguientes situaciones:
- \(H_1: \mu > \mu_0\), región de rechazo \(Z_0\geq 1.88\).
- \(H_1: \mu < \mu_0\), región de rechazo \(Z_0\leq -2.75\).
- \(H_1: \mu \neq \mu_0\), región de rechazo \(Z_0\geq 2.88\) o \(Z_0\leq -2.88\).
Ejercicio 3.7 Un fabricante de cajas de cartón afirma que sus cajas tienen un peso promedio de 5 kg. Para verificar esta afirmación, un cliente selecciona al azar 25 cajas y encuentra que el peso promedio es de 4.8 kg con una desviación estándar conocida de 0.5 kg. ¿Hay suficiente evidencia para rechazar la afirmación del fabricante al nivel de significancia del 5%?
Ejercicio 3.8 Se sabe que la duración de las baterías sigue una distribución normal con media 290 horas y varianza poblacional conocida de 64 horas. Bajo una nueva fórmula de fabricación, se tomó una muestra aleatoria de 36 dispositivos móviles y se registró una duración media muestral de 280 horas. Utilizando un nivel de significancia del 5%, ¿se puede concluir con suficiente evidencia estadística que la duración media de las baterías ha mejorado significativamente después de aplicar una nueva fórmula en su fabricación?
Ejercicio 3.9 Un cirujano necesita evaluar si los pacientes se recuperan en un promedio en un tiempo menor a 5 días después de una cirugía. Para probar su afirmación, un internista toma una muestra aleatoria de 20 pacientes y encuentra que la duración promedio de recuperación es de 6 días, con una desviación estándar conocida de 1.5 días. ¿Hay suficiente evidencia para rechazar la afirmación del cirujano al nivel de significancia del 10%?
Ejercicio 3.10 Se requiere estudiar si la cantidad promedio de cafeína en una taza de café es menor a 100 mg. Para probar esta hipótesis, se toma una muestra aleatoria de 50 tazas de café y se encuentra que la cantidad promedio de cafeína es de 105 mg, con una desviación estándar conocida de 15 mg. ¿Hay suficiente evidencia para rechazar la hipótesis nula al nivel de significancia del 5%?
Ejercicio 3.11 Se desea evaluar si la altura promedio de una población de girasoles es distinta de 150 cm. Para ello, se selecciona una muestra aleatoria de 30 girasoles y se encuentra que la altura promedio es de 155 cm, con una desviación estándar conocida de 5 cm. ¿Hay suficiente evidencia para rechazar la hipótesis nula al nivel de significancia del 1%?
3.2.2 Varianza poblacional desconocida
De igual manera a lo expuesto en el primer caso, los pasos a seguir para probar una hipótesis son los mismos, y se mantendrá así para cualquier caso.
- Plantear las hipótesis nula y alternativa
- Identificar o establecer el nivel de significancia.
- Identificar los datos muestrales y poblacionales con los que se cuenta.
- Utilizar alguna de las reglas de decisión (Estadístico de prueba, valor-p o intervalo de confianza).
- Concluir
En la situación de una prueba de hipótesis de la media, en la cual lo datos distribuyen normal y la varianza poblacional es desconocida, los criterios de rechazo son similares a los vistos anteriormente, sin embargo, cambia la distribución del estadístico de prueba, tal como se muestra en la tabla 3.5.
| Hipótesis nula | Estadístico de prueba | Hipótesis alternativa | Criterio de rechazo |
|---|---|---|---|
| \(H_0: \mu = \mu_0\) | \(t_0 = \displaystyle\frac{\bar{x}-\mu_0}{S/\sqrt{n}}\) | \(H_1: \mu \neq \mu_0\) | \(|t_0| \geq t_{1-\alpha/2, n-1}\) |
| \(H_1: \mu \gt \mu_0\) | \(t_0 \geq t_{1-\alpha,n-1}\) | ||
| \(H_1: \mu \lt \mu_0\) | \(t_0 \leq t_{\alpha,n-1}\) |
donde \(n\) corresponde al tamaño de la muestra.
Ejemplo 3.4 Utilizando la base de datos Imacec, establezca si hay suficiente evidencia estadística para afirmar que, el valor promedio del Imacec de cada sector por separado es mayor a 98.54167 (denote este valor por \(\mu_0\)). Establezca las hipótesis respectivas, estadísticos y criterios de rechazo, utilizando una significancia del 10%. Asuma que las variables distribuyen normal y tienen varianza poblacional desconocida.
En este caso al contar con una base de datos (y para este tipo de prueba), podemos hacer uso directamente de R para obtener el estadístico de prueba, valor-p e intervalo de confianza asociado.
Iniciamos con la prueba de hipótesis para el sector de minería.
- \(\mu:\) Media del Imacec de Minería.
Luego, haciendo uso de R obtenemos los elementos necesario para rechazar o no \(H_0\).
# Cargue previamente la base de datos, guardándola con el nombre "df"
# Minería
t.test( # Prueba de hipótesis para el estadístico con distribución t-student
x = df$Mineria, # Valores del Imacec de Minería
alternative = "greater", # Signo de desigualdad de la hipótesis alternativa
mu = 98.54167, # Valor del Mu_0
conf.level = 0.9 # Confianza = 1 - alfa
)##
## One Sample t-test
##
## data: df$Mineria
## t = -1.2773, df = 53, p-value = 0.8965
## alternative hypothesis: true mean is greater than 98.54167
## 90 percent confidence interval:
## 96.21024 Inf
## sample estimates:
## mean of x
## 97.38519Método del valor-p
Verificación del criterio de rechazo: Valor-p \(\leq \alpha\).
## [1] FALSEInterpretación utilizando el método del valor-p: El valor-p de 0.8965 no es menor o igual a la significancia del 0.1, por lo cual, no existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, no existe suficiente evidencia para apoyar la afirmación de que el valor promedio del Imacec del sector de Minería es mayor a 98.54167. Considerando una confianza del 90%.
Método del valor crítico
Verificación del criterio de rechazo: \(t_0 \geq t_{1-\alpha,n-1}\).
## [1] 1.29773## [1] FALSEInterpretación utilizando el método del valor crítico: El estadístico de prueba de -1.2773 no es mayor o igual al valor crítico de 1.2977, por lo cual, no existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, no existe suficiente evidencia para apoyar la afirmación de que el valor promedio del Imacec del sector de Minería es mayor a 98.54167. Considerando una confianza del 90%.
Método del intervalo de confianza
Verificación del criterio de rechazo: \(\mu_0 \notin\) IC.
## [1] FALSEInterpretación utilizando el método del intervalo de confianza: El intervalo de confianza \((96.21024, \infty)\) contiene al valor de \(\mu_0 = 98.54167\), por lo cual, no existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, no existe suficiente evidencia para apoyar la afirmación de que el valor promedio del Imacec del sector de Minería es mayor a 98.54167. Considerando una confianza del 90%.
La prueba de hipótesis para el sector de industria es la siguiente.
- \(\mu:\) Media del Imacec de Industria.
# Industria
t.test( # Prueba de hipótesis para el estadístico con distribución t-student
x = df$Industria, # Valores del Imacec de Industria
alternative = "greater", # Signo de desigualdad de la hipótesis alternativa
mu = 98.54167, # Valor del Mu_0
conf.level = 0.9 # Confianza = 1 - alfa
)##
## One Sample t-test
##
## data: df$Industria
## t = 1.3678, df = 53, p-value = 0.08857
## alternative hypothesis: true mean is greater than 98.54167
## 90 percent confidence interval:
## 98.60095 Inf
## sample estimates:
## mean of x
## 99.69815Método del valor-p
Verificación del criterio de rechazo: Valor-p \(\leq \alpha\).
## [1] TRUEInterpretación utilizando el método del valor-p: El valor-p de 0.8965 menor o igual a la significancia del 0.1, por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que el valor promedio del Imacec del sector de Industria es mayor a 98.54167. Considerando una confianza del 90%.
Método del valor crítico
Verificación del criterio de rechazo: \(t_0 \geq t_{1-\alpha,n-1}\).
## [1] 1.29773## [1] TRUEInterpretación utilizando el método del valor crítico: El estadístico de prueba de 1.3678 es mayor o igual al valor crítico de 1.2977, por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que el valor promedio del Imacec del sector de Industria es mayor a 98.54167. Considerando una confianza del 90%.
Método del intervalo de confianza
Verificación del criterio de rechazo: \(\mu_0 \notin\) IC.
## [1] TRUEInterpretación utilizando el método del intervalo de confianza: El intervalo de confianza \((98.6009, \infty)\) no contiene al valor de \(\mu_0 = 98.54167\), por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que el valor promedio del Imacec del sector de Industria es mayor a 98.54167. Considerando una confianza del 90%.
Ejercicio 3.12 Utilizando la base de datos Imacec, establezca si hay suficiente evidencia estadística para afirmar que, el valor promedio del Imacec de cada sector durante el año 2022 es mayor 96.89167. Establezca las hipótesis, estadísticos y criterios de rechazo. Utilice una significancia del 7%. Además, asuma que las variables distribuyen normal y tienen varianza poblacional desconocida. Concluya.
Ejercicio 3.13 El control de emisión de residuos ha sido un tema que ha cobrado gran importancia en los últimos 20 años debido a los efectos del calentamiento global. Uno de los tantos residuos que contamina el aire es el Metano (CH4). Para estudiar este fenómeno haremos uso de la base metano.csv, la cual contiene los siguientes datos:
- Año: año en el que se realiza la medición de emisión de CH4.
- Mes: mes del año en el que se realiza la medición de emisión de CH4.
- CH4: concentración de CH4 (partes por miles de millones) en un muestra de aire.
Establezca si hay suficiente evidencia estadística para afirmar lo siguiente:
- La concentración promedio de metano es distinta a 1700 partes por miles de millones.
- La concentración promedio de metano del año 2021 es superior a 1780 partes por miles de millones.
- La concentración promedio de metano del periodo en el periodo de años 2019 - 2022 (inclusive) es inferior a 1750 partes por miles de millones.
Establezca las hipótesis respectivas, estadísticos y criterios de rechazo, utilice una significancia del 7%. Asuma que las variables distribuyen normal y tienen varianza poblacional desconocida. Concluya.
Ejercicio 3.14 Utilizando la base de datos ICC, estudie si hay suficiente evidencia estadística para afirmar lo siguiente:
- El promedio del ICC es distinto a 100 puntos.
- El promedio del ICC en Francia es menor a 105 puntos.
- El promedio del ICC en Alemania es mayor a 107 puntos.
Establezca las hipótesis, estadísticos y criterios de rechazo. Utilice una significancia del 12%. Además, asuma que las variables distribuyen normal y tienen varianza poblacional desconocida. Concluya.
3.3 Prueba de hipótesis para la diferencia de medias
En esta sección se continúa con el estudio de la inferencia estadística, específicamente para la diferencia entre dos medias poblacionales. Por ejemplo, quizá desee obtener una estimación por intervalo para la diferencia entre el salario inicial medio de la población de hombres y el salario inicial medio de la población de mujeres (Anderson et al., 2008, página 395). Para este tipo de pruebas, se requiere que las distribuciones poblacionales de las variables sean normales e independientes, lo cual, se asumirá en los enunciados de ejemplos y/o ejercicios según corresponda.
3.3.1 Varianzas poblacionales conocidas
El primero de los tres casos corresponde al de varianzas poblacionales conocidas. La tabla 3.6 da cuenta del estadístico de prueba asociado las respectivas hipótesis, además de los criterios asociados al valor crítico correspondiente.
| Hipótesis nula | Estadístico de prueba | Hipótesis alternativa | Criterio de rechazo |
|---|---|---|---|
| \(H_0: \mu_X - \mu_Y = \delta_0\) | \(Z_0 = \displaystyle\frac{\bar{x} - \bar{y} - \delta_0}{\sqrt{\sigma^2_X/n_X + \sigma^2_Y/n_Y}}\) | \(H_1: \mu_X - \mu_Y \neq \delta_0\) | \(|Z_0| \geq Z_{1-\alpha/2}\) |
| \(H_1: \mu_X - \mu_Y \gt \delta_0\) | \(Z_0 \geq Z_{1-\alpha}\) | ||
| \(H_1: \mu_X - \mu_Y \lt \delta_0\) | \(Z_0 \leq Z_{\alpha}\) |
Ejemplo 3.5 En dos ciudades se llevó acabo una encuesta sobre el costo de la vida, en relación al gasto promedio en alimentación en familias constituidas por cuatro personas. De cada ciudad se seleccionó aleatoriamente una muestra de 20 familias y se observaron sus gastos semanales en alimentación. Las medias muestrales y desviaciones estándar poblacionales fueron las siguientes:
\[\begin{equation} \notag \begin{split} \bar{x} = 135, & \text{ } \sigma_X = 15\\ \bar{y} = 122, & \text{ } \sigma_Y = 10 \end{split} \end{equation}\]Si se supone que se muestrearon dos poblaciones independientes con distribución normal cada una, analizar si existe una diferencia real entre ambas medias. Considere una confianza del 95%.
Las hipótesis a plantear son las siguientes.
- \(\mu_X:\) gasto medio semanal en alimentación en la ciudad X.
- \(\mu_Y:\) gasto medio semanal en alimentación en la ciudad Y.
Al igual que en la prueba para una media cuando se conoce la varianza poblacional, esta prueba no tiene una implementación directa en R, por lo que construiremos manualmente los métodos de rechazo.
Método del valor-p
Verificación del criterio de rechazo: Valor-p \(\leq \alpha\).
# Cálculo del estadístico de prueba z0 = (x.barra - y.barra - delta0)/sqrt(sigma.x^2/nx+sigma.y^2/ny) z0## [1] 3.224903## [1] 0.001260153## [1] TRUEInterpretación utilizando el método del valor-p: El valor-p de 0.0012 es menor o igual a la significancia del 0.05, por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que existe diferencia entre los gastos de alimentación promedio entre las familias de ambas ciudades. Considerando una confianza del 95%.
Método del valor crítico
Verificación del criterio de rechazo: \(|Z_0| \geq Z_{1-\alpha/2}\).
## [1] 1.959964## [1] TRUEInterpretación utilizando el método del valor crítico: El valor absoluto del estadístico de prueba de 3.2249 es mayor o igual al valor crítico de 1.9599, por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que existe diferencia entre los gastos de alimentación promedio entre las familias de ambas ciudades. Considerando una confianza del 95%.
Método del intervalo de confianza
Verificación del criterio de rechazo: \(\delta_0 \notin\) IC.
El intervalo de confianza a construir es:
\[\begin{equation} \notag \left(\bar{x} - \bar{y} \pm Z_{1-\alpha/2}\sqrt{\frac{\sigma_X^2}{n_X} + \frac{\sigma_Y^2}{n_Y}}\right) \end{equation}\]# Cálculo de los límites del intervalo de confianza Limite_inferior = x.barra - y.barra - qnorm(1-alfa/2)*sqrt(sigma.x^2/nx + sigma.y^2/ny) Limite_superior = x.barra - y.barra + qnorm(1-alfa/2)*sqrt(sigma.x^2/nx + sigma.y^2/ny) c(Limite_inferior, Limite_superior)## [1] 5.099133 20.900867## [1] TRUEInterpretación utilizando el método del intervalo de confianza: El intervalo de confianza \((5.0991, 20.9008)\) no contiene al valor de \(\delta_0 = 0\), por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que existe diferencia entre los gastos de alimentación promedio entre las familias de ambas ciudades. Considerando una confianza del 95%.
Ejercicio 3.15 La base control+cuotas.csv contiene datos de los valores cuota de los primeros tres meses del año 2022 de las AFP Plan Vital y Provida, específicamente de un fondo A de un APV.
Se está interesado en saber si, la media de los valores cuota de Plan Vital supera al de Provida por más de 30000 pesos. Considere una confianza del 99%. Plantee y pruebe una hipótesis para la diferencia de medias, considerando \(\sigma^2_{\text{Provida}} = 1165833\) y \(\sigma^2_{\text{Plan Vital}} = 3393141\). Utilice todos los métodos de rechazo.
3.3.2 Varianzas poblacionales desconocidas e iguales
Para el segundo caso, las varianzas poblacionales son desconocidas, sin embargo, los valores de estas varianzas poblacionales pueden ser iguales o distintos. La tabla 3.7 refleja el estadístico de prueba y los criterios de rechazo asociados al método del valor crítico, para el caso en que los valores de las varianzas poblacionaes desconocidas son iguales.
| Hipótesis nula | Estadístico de prueba | Hipótesis alternativa | Criterio de rechazo |
|---|---|---|---|
| \(H_0: \mu_X - \mu_Y = \delta_0\) | \(t_0 = \displaystyle\frac{\bar{x} - \bar{y} - \delta_0}{S_p\sqrt{1/n_X + 1/n_Y}}\) | \(H_1: \mu_X - \mu_Y \neq \delta_0\) | \(|t_0| \geq t_{1-\alpha/2,k}\) |
| \(H_1: \mu_X - \mu_Y \gt \delta_0\) | \(t_0 \geq t_{1-\alpha,k}\) | ||
| \(H_1: \mu_X - \mu_Y \lt \delta_0\) | \(t_0 \leq t_{\alpha,k}\) |
Donde los valores de \(k\) y \(S_p\) son los siguientes.
\[\begin{equation} \notag k = n_X + n_Y-2 \end{equation}\] \[\begin{equation} \notag S_p^2 = \frac{(n_X-1)S_X^2 + (n_Y-1)S_Y^2}{n_X+n_Y-2} \end{equation}\]Ejemplo 3.6 Considere la base de datos ICC. Se está interesado en saber si el valor promedio del ICC en Alemania menos el de Francia es menor a 1.1. Elabore una prueba de hipótesis para analizar este interés con un 90% de confianza. Concluya utilizando el valor – p. Además, que las varianzas poblaciones son iguales.
- \(\mu_X:\) media del ICC de Alemania.
- \(\mu_Y:\) media del ICC de Francia.
# Cargue previamente la base guardándola con el nombre "datos"
ICC_Alemania = datos$ICC[datos$Locacion == "DEU"] # Valores del ICC de Alemania
ICC_Francia = datos$ICC[datos$Locacion == "FRA"] # Valores del ICC de Francia
t.test(
x = ICC_Alemania,
y = ICC_Francia,
conf.level = 0.9, # Confianza
alternative = "less", # Signo según la hipótesis alternativa
mu = 1.1, # Valor de delta0
var.equal = T # Comando que indica que las varianzas son iguales
)##
## Two Sample t-test
##
## data: ICC_Alemania and ICC_Francia
## t = 0.10482, df = 132, p-value = 0.5417
## alternative hypothesis: true difference in means is less than 1.1
## 90 percent confidence interval:
## -Inf 1.404981
## sample estimates:
## mean of x mean of y
## 100.74328 99.62033Método del valor-p
Verificación del criterio de rechazo: Valor-p \(\leq \alpha\).
## [1] FALSEInterpretación utilizando el método del valor-p: El valor-p de 0.5417 no es menor o igual a la significancia del 0.1, por lo cual, no existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, no existe suficiente evidencia para apoyar la afirmación de que el valor promedio del ICC en Alemania menos el de Francia es menor a 1.1. Considerando una confianza del 90%.
Método del valor crítico
Verificación del criterio de rechazo: \(t_0 \leq t_{\alpha,k}\).
## [1] -1.287998## [1] FALSEInterpretación utilizando el método del valor crítico: El estadístico de prueba de 0.10482 no es menor o igual al valor crítico de -1.2879, por lo cual, no existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, no existe suficiente evidencia para apoyar la afirmación de que el valor promedio del ICC en Alemania menos el de Francia es menor a 1.1. Considerando una confianza del 90%.
Método del intervalo de confianza
Verificación del criterio de rechazo: \(\delta_0 \notin\) IC.
## [1] FALSEInterpretación utilizando el método del intervalo de confianza: El intervalo de confianza \((-\infty, 1.4049)\) contiene al valor de \(\delta_0 = 1.1\), por lo cual, no existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, no existe suficiente evidencia para apoyar la afirmación de que el valor promedio del ICC en Alemania menos el de Francia es menor a 1.1. Considerando una confianza del 90%.
Ejercicio 3.16 Utilizando la base de datos ICC, plantee y pruebe un hipótesis, para verificar si para el año 2019 existe una diferencia mayor a 1.2 entre el ICC promedio de Polonia e Italia, con una confianza del 93%. Utilice el método del intervalo de confianza. Además, asuma que las varianzas poblacionales son desconocidas e iguales.
Ejercicio 3.17 Los desastres naturales pueden ocurrir en cualquier lugar y, cuando estos se dan lugares donde la población es densa, pueden afectar a diversos componentes de la sociedad, entre ellos la economía, ya que los daños pueden traducirse en pérdida o destrucción de bienes de capital, niveles de ahorro, incremento de precios, entre otros efectos.
Para estudiar este fenómeno, utilizaremos la base de datos terremotos.csv, la cual contiene datos sobre los terremotos ocurridos a nivel mundial entre los años 1900 y 2014. Las columnas de la base de datos son:
- Año: año de ocurrencia del terremoto.
- Latitud: grados decimales de la coordenada de latitud (valores negativos para latitudes del sur).
- Longitud: grados decimales de la coordenada de longitud (valores negativos para longitudes occidentales).
- Profundidad: profundidad del evento en kilómetros.
- Magnitud: magnitud del evento (la escala no es fija, ya que, a través de los años, la escala a cambiado según el método de medición. Sin embargo, todos las magnitudes son comparables, indicando que a mayor magnitud, mayor es la intensidad en movimiento/fuerza del terremoto).
A continuación elabore las siguiente pruebas.
Establezca una prueba de hipótesis con un 93% de confianza para estudiar si, existe diferencia entre los promedios de las profundidades de los terremotos ocurridos en los años 1976 y 1986. Asuma varianzas poblacionales desconocidas e iguales.
Establezca una prueba de hipótesis con un 97% de confianza para estudiar si, el promedio las magnitudes de los terremotos en los años 1900 y 1922 es mayor al de los años 2010 y 2014, por más de 0.5 unidades de medida. Asuma varianzas poblacionales desconocidas e iguales.
3.3.3 Varianzas poblacionales desconocidas y distintas
El último de los casos, las varianzas poblacionales son desconocidas y distintas. El detalle del estadístico de prueba y los criterios del método del valor crítico asociados se encuentran en la tabla 3.8.
| Hipótesis nula | Estadístico de prueba | Hipótesis alternativa | Criterio de rechazo |
|---|---|---|---|
| \(H_0: \mu_X - \mu_Y = \delta_0\) | \(t_0 = \displaystyle\frac{\bar{x} - \bar{y} - \delta_0}{\sqrt{S^2_X/n_X + S^2_Y/n_Y}}\) | \(H_1: \mu_X - \mu_Y \neq \delta_0\) | \(|t_0| \geq t_{1-\alpha/2,k}\) |
| \(H_1: \mu_X - \mu_Y \gt \delta_0\) | \(t_0 \geq t_{1-\alpha,k}\) | ||
| \(H_1: \mu_X - \mu_Y \lt \delta_0\) | \(t_0 \leq t_{\alpha,k}\) |
dónde \(k\) es el entero más cercano a
\[\begin{equation} \notag \frac{(S_X^2/n_X + S_Y^2/n_Y)^2}{(S_X^2/n_X)^2/(n_X-1) + (S_Y^2/n_Y)^2/(n_Y-1)} \end{equation}\]Ejemplo 3.7 Utilizando la base de datos del ICC, establecer una prueba de hipótesis para verificar si el ICC promedio de Italia es mayor al de Francia, con una significancia del 3%. Asumiendo que las varianzas poblacionales son desconocidas y distintas.
Las hipótesis a plantear son las siguientes.
- \(\mu_X:\) media del ICC de Italia
- \(\mu_Y:\) media del ICC de Francia.
Luego, la prueba se ejecuta con el siguiente código.
# Cargue previamente la base guardándola con el nombre "datos"
ICC_Italia = datos$ICC[datos$Locacion == "ITA"] # Valores del ICC de Italia
ICC_Francia = datos$ICC[datos$Locacion == "FRA"] # Valores del ICC de Francia
t.test(
x = ICC_Italia,
y = ICC_Francia,
conf.level = 0.97, # Confianza
alternative = "greater", # Signo según la hipótesis alternativa
mu = 0, # Valor de delta0
var.equal = F # Comando que indica que las varianzas son distintas
)##
## Welch Two Sample t-test
##
## data: ICC_Italia and ICC_Francia
## t = 4.0794, df = 131.74, p-value = 3.886e-05
## alternative hypothesis: true difference in means is greater than 0
## 97 percent confidence interval:
## 0.4887855 Inf
## sample estimates:
## mean of x mean of y
## 100.53403 99.62033Método del valor-p
Verificación del criterio de rechazo: Valor-p \(\leq \alpha\).
## [1] TRUEInterpretación utilizando el método del valor-p: El valor-p de 3.886e-05 es menor o igual a la significancia del 0.03, por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que el ICC promedio de Italia es mayor al de Francia. Considerando una confianza del 97%.
Método del valor crítico
Verificación del criterio de rechazo: \(t_0 \geq t_{1-\alpha,k}\).
## [1] 1.897095## [1] TRUEInterpretación utilizando el método del valor crítico: El estadístico de prueba de 4.0794 es mayor o igual al valor crítico de 1.8970, por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que el ICC promedio de Italia es mayor al de Francia. Considerando una confianza del 97%.
Método del intervalo de confianza
Verificación del criterio de rechazo: \(\delta_0 \notin\) IC.
## [1] TRUEInterpretación utilizando el método del intervalo de confianza: El intervalo de confianza \((0.4887,\infty)\) no contiene al valor de \(\delta_0 = 0\), por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que el ICC promedio de Italia es mayor al de Francia. Considerando una confianza del 97%.
Ejercicio 3.18 La energía renovable es esencial para reducir las emisiones de carbono y mitigar el cambio climático. Además, la energía renovable mejora la salud pública, crea nuevos puestos de trabajo, garantiza la seguridad energética a través de la diversificación y estabiliza los precios de la energía.
La importancia de alejarse de los combustibles fósiles y acercarse a las fuentes renovables no puede subestimarse. Como tal, este conjunto de datos (energia.csv) rastrea el crecimiento del sector renovable del Reino Unido desde 1990 hasta 2020. Las columnas de la base de datos son las siguientes:
- Ano: año de medición.
- Renovables.Residuos: Energía procedente de fuentes renovables y de residuos.
- Consumo.Total: Consumo total de energía de combustibles primarios y equivalentes.
- Hidroelectrica: Consumo de energía producido por hidroeléctricas.
- Viento.Olas: Consumo de energía producido por vientos, olas y mareas.
- Solar Consumo de energía producido por paneles fotovoltaicos.
- Geo: Consumo de energía producido por acuíferos geotérmicos.
- Vertedero: Consumo de energía producido por gases de vertedero.
- Gas: Consumo de energía producido por gases de aguas residuales.
La unidad de energía utilizada en este conjunto de datos es la megatonelada equivalente de petróleo (mtep).
A continuación elabore las siguiente pruebas.
Elabore una prueba de hipótesis con una confianza del 97% para estudiar si, existe diferencia entre el promedio de energía consumida mediante gases de aguas residuales y la consumida mediante hidroeléctricas. Asuma que las varianzas poblacionales son desconocidas y distintas.
Elabore una prueba de hipótesis con una confianza del 98% para estudiar si, la diferencia del promedio de la energía consumida por gases de vertederos es mayor a la consumida por paneles fotovoltaicos. Asuma que las varianzas poblacionales son desconocidas y distintas.
Elabore un intervalo de confianza al 99% para estudiar si, el promedio del consumo total de energía durante el periodo 2004 - 2020 es menor al del periodo 1990 - 2003 por más de 40 unidades. Asuma que las varianzas poblacionales son desconocidas y distintas.
3.4 Prueba de hipótesis para comparación de varianzas
En esta sección se extiende el estudio a las varianzas poblacionales, con al finalidad de estableces si estas son iguales o distintas. Para ello, se requiere que las distribuciones poblacionales de las variables de estudios sean normales e independientes, lo cual, se asumirá en los enunciados de los ejemplos y/o ejercicios según corresponda.
| Hipótesis nula | Estadístico de prueba | Hipótesis alternativa | Criterio de rechazo |
|---|---|---|---|
| \(H_0: \sigma_X^2 = \sigma_Y^2\) | \(f_0 = S_X^2/S_Y^2\) | \(H_1: \sigma_X^2 \neq \sigma_Y^2\) | \(f_0 \geq f_{1-\alpha/2,n_X-1,n_Y-1} \vee\) |
| \(f_0 \leq f_{\alpha/2,n_X-1,n_Y-1}\) | |||
| \(H_1: \sigma_X^2 \gt \sigma_Y^2\) | \(f_0 \geq f_{1-\alpha,n_X-1,n_Y-1}\) | ||
| \(H_1: \sigma_X^2 \lt \sigma_Y^2\) | \(f_0 \leq f_{\alpha,n_X-1,n_Y-1}\) |
Gracias a esta prueba, es posible determinar de antemano si las varianzas poblacionales son iguales o distintas asumiendo que son desconocidas, lo cual, permite elegir posteriormente que tipo de pruebas para la diferencia de medias se debe realizar.
Ejemplo 3.8 Utilizando la base de datos del ICC, establecer una prueba de hipótesis para verificar si el ICC promedio de España es distinto al de Polonia, con una significancia del 4%. Asumiendo muestras independientes.
En primer lugar se establece la prueba de hipótesis para la igualdad de varianzas.
- \(\sigma^2_X:\) varianza del ICC de España.
- \(\sigma^2_Y:\) varianza del ICC de Polonia.
El código para realizar esta prueba es el siguiente.
# Cargue previamente la base guardándola con el nombre "datos"
ICC_Espana = datos$ICC[datos$Locacion == "ESP"] # Valores del ICC de España
ICC_Polonia = datos$ICC[datos$Locacion == "POL"] # Valores del ICC de Polonia
var.test(
x = ICC_Espana,
y = ICC_Polonia,
alternative = "two.sided", # Tipo de hipótesis alternativa
conf.level = 0.96 # Confianza
)##
## F test to compare two variances
##
## data: ICC_Espana and ICC_Polonia
## F = 3.5354, num df = 66, denom df = 66, p-value = 7.241e-07
## alternative hypothesis: true ratio of variances is not equal to 1
## 96 percent confidence interval:
## 2.122496 5.888850
## sample estimates:
## ratio of variances
## 3.535401Método del valor-p
Verificación del criterio de rechazo: Valor-p \(\leq \alpha\).
## [1] TRUEInterpretación utilizando el método del valor-p: El valor-p de 3.886e-05 es menor o igual a la significancia del 0.03, por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que las varianzas poblacionales son desconocidas y distintas. Considerando una confianza del 96%.
Método del valor crítico
Verificación del criterio de rechazo: \(f_0 \geq f_{1-\alpha/2,n_X-1,n_Y-1} \vee f_0 \leq f_{\alpha/2,n_X-1,n_Y-1}\).
# Cálculo del valor crítico valor_critico_1 = qf(1-0.04/2, df1 = 66, df2 = 66) valor_critico_2 = qf(0.04/2, df1 = 66, df2 = 66) c(valor_critico_1, valor_critico_2)## [1] 1.6656807 0.6003551## [1] TRUEInterpretación utilizando el método del valor crítico: El estadístico de prueba de 3.5354 es mayor o igual, o, menor o igual a los valores críticos de 1.6656 y 0.6003 respectivamente, por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que las varianzas poblacionales son desconocidas y distintas. Considerando una confianza del 96%.
Método del intervalo de confianza
Verificación del criterio de rechazo: \(1 \notin\) IC.
# Verificación del criterio Limite_inferior = 2.122496 Limite_superior = 5.888850 1 < Limite_inferior | 1 > Limite_superior## [1] TRUEInterpretación utilizando el método del intervalo de confianza: El intervalo de confianza \((2.1224, 5.8888)\) no contiene al 1, por lo cual, existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, existe suficiente evidencia para apoyar la afirmación de que las varianzas poblacionales son desconocidas y distintas. Considerando una confianza del 96%.
Luego, las hipótesis para la diferencia de medias son las siguientes.
- \(\mu_X:\) media del ICC de España.
- \(\mu_Y:\) media del ICC de Polonia.
t.test(
x = ICC_Espana,
y = ICC_Polonia,
alternative = "two.sided", # Tipo de hipótesis alternativa
conf.level = 0.96, # Confianza
mu = 0, # delta0
var.equal = F # Varianzas poblacionales distintas
)##
## Welch Two Sample t-test
##
## data: ICC_Espana and ICC_Polonia
## t = -1.4661, df = 100.57, p-value = 0.1458
## alternative hypothesis: true difference in means is not equal to 0
## 96 percent confidence interval:
## -1.4752851 0.2556696
## sample estimates:
## mean of x mean of y
## 100.3420 100.9518Método del valor-p
Verificación del criterio de rechazo: Valor-p \(\leq \alpha\).
## [1] FALSEInterpretación utilizando el método del valor-p: El valor-p de 0.1458 no es menor o igual a la significancia del 0.04, por lo cual, no existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, no existe suficiente evidencia para apoyar la afirmación de el ICC promedio de España es distinto al de Polonia. Considerando una confianza del 96%.
Método del valor crítico
Verificación del criterio de rechazo: \(|t_0| \geq t_{1-\alpha/2,k}\).
## [1] 2.080612## [1] FALSEInterpretación utilizando el método del valor crítico: El valor absoluto del estadístico de prueba de 1.4661 no es mayor o igual al valor crítico de 2.0806, por lo cual, no existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, no existe suficiente evidencia para apoyar la afirmación de el ICC promedio de España es distinto al de Polonia. Considerando una confianza del 96%.
Método del intervalo de confianza
Verificación del criterio de rechazo: \(\delta_0 \notin\) IC.
# Verificación del criterio Limite_inferior = -1.4752 Limite_superior = 0.2556 0 < Limite_inferior | 0 > Limite_superior## [1] FALSEInterpretación utilizando el método del intervalo de confianza: El intervalo de confianza \((-1.4752, 0.25568)\) contiene al valor de \(\delta_0 = 0\), por lo cual, no existe suficiente evidencia estadística para rechazar la hipótesis nula, es decir, no existe suficiente evidencia para apoyar la afirmación de el ICC promedio de España es distinto al de Polonia. Considerando una confianza del 96%.
Ejercicio 3.19 La contaminación del aire representa un importante riesgo medioambiental para la salud. Mediante la disminución de los niveles de contaminación del aire los países pueden reducir la carga de morbilidad derivada de accidentes cerebrovasculares, cánceres de pulmón y neumopatías crónicas y agudas, entre ellas el asma. Cuanto más bajos sean los niveles de contaminación del aire mejor será la salud cardiovascular y respiratoria de la población, tanto a largo como a corto plazo.
Por lo anteriormente mencionado, utilizaremos una base de datos propia de R (airquality) para estudiar la calidad del aire. Esta base de datos contiene mediciones diarias de la calidad del aire en Nueva York, de mayo a septiembre de 1973. Las columnas son las siguientes:
- Ozone: Ozono medio en partes por billón.
- Solar.R: Radiación solar en Langleys (unidad de medida de la radiación solar).
- Wind: Velocidad promedio del viento en millas por hora.
- Temp: Temperatura máxima diaria en grados Fahrenheit.
- Month: Mes de medición.
- Day: Día de medición.
Elimine los datos faltantes de la base de datos con el comando na.omit(). A continuación:
Plantee y pruebe una hipótesis para estudiar la diferencia entre el promedio de concentración de Ozono en los primeros 15 días del mes y el promedio de concentración de Ozono en el resto de los días del mes. Utilice una confianza del 92%. Interprete los intervalos de confianza y valores - p de todas las pruebas a utilizar.
Ejercicio 3.20 La base de datos CO2 (incroporrada en R) contiene datos de un experimento sobre la tolerancia al frío de la especie de pasto Echinochloa crus-galli. Las columnas son las siguientes:
- Plant: Identificador del tipo de planta.
- Type: Lugar de origen de la planta.
- Treatment: indica si la planta fue refrigerada (chilled) o no (nonchilled).
- conc: Concentraciones ambientales de dióxido de carbono (mL/L).
- uptake: Tasas de absorción de dióxido de carbono (\(umol/m^2\) seg) de las plantas.
A continuación, plantee y pruebe una hipótesis para estudiar si, la diferencia entre el promedio de la tasa de absorción de dióxido de carbono de las dos zonas medidas está a favor de Mississippi. Utilice una confianza del 96%. Haga uso de todos los métodos de rechazo. Interprete.
3.5 Prueba de hipótesis para la diferencia de proporciones
Después de presentar métodos para comparar las medidas de dos poblaciones diferentes, ahora se presta atención a la comparación de dos proporciones de población. Las proporciones se plantear de la siguiente manera (Devore, 2008, página 353).
\[\begin{equation} \notag \begin{split} p_1 &= \text{la proporción de éxitos en la población 1}\\ p_2 &= \text{la proporción de éxitos en la población 2}\\ \end{split} \end{equation}\]La prueba de hipótesis que permite comparar la diferencia entre estás proporciones, asumiendo que las distribuciones poblacionales de las variables son binomiales e independientes, es la siguiente
| Hipótesis nula | Estadístico de prueba | Hipótesis alternativa | Criterio de rechazo |
|---|---|---|---|
| \(H_0: p_X - p_Y = \delta_0\) | \(Z_0 = \displaystyle\frac{\widehat{p}_X-\widehat{p}_Y-\delta_0}{\sqrt{\widehat{p}\widehat{q}\left( \frac{1}{n_X} + \frac{1}{n_Y} \right)}}\) | \(H_1: p_X - p_Y \neq \delta_0\) | \(|Z_0| \geq Z_{1-\alpha/2}\) |
| \(H_1: p_X - p_Y \gt \delta_0\) | \(Z_0 \geq Z_{1-\alpha}\) | ||
| \(H_1: p_X - p_Y \lt \delta_0\) | \(Z_0 \leq Z_{\alpha}\) |
donde
\[\begin{equation} \notag \begin{split} \widehat{p} &= \frac{n_X\widehat{p}_X}{n_X+n_Y} + \frac{n_Y\widehat{p}_Y}{n_X+n_Y}\\ \widehat{q} & = 1 - \widehat{p} \end{split} \end{equation}\]Existen otros estadísticos de prueba que se pueden elaborar para este tipo de hipótesis, en particular el que usa R es el estadístico \(\chi^2\). Este estadístico requiere que los datos estén dispuestos en una tabla, tal como se muestra a continuación.
| Grupo 1 | Grupo 2 | |
|---|---|---|
| Éxitos | \(O_1\) | \(O_2\) |
| Fracasos | \(O_3\) | \(O_4\) |
El estadístico en cuestión es el siguiente.
\[\begin{equation} \notag \chi^2_0 = \sum_{i=1}^n\frac{(O_i-E_i)^2}{E_i} \end{equation}\]Donde \(E_i\) y \(O_i\) corresponden a la frecuencia esperada y observada en cada celda respectivamente. Las frecuencias esperadas se calculan como el producto de las frecuencias marginales, divido por el total de observaciones. Cabe mencionar que, R solo tiene la capacidad de ejecutar esta prueba cuando \(\delta_0 = 0\), el cual, es el caso en el que nos concentraremos.
Los supuestos asociados a esta prueba de hipótesis se asumirán para los enunciados de los ejemplos y/o ejercicios según corresponda.
Ejemplo 3.9 Se pretende comparar si existe diferencias en la eficacia de un nuevo fármaco, medido como proporción, entre hombres y mujeres. Los datos se aprecian en la siguiente tabla.
| Hombre | Mujer | |
|---|---|---|
| Sí | 20 | 50 |
| No | 120 | 110 |
La prueba de hipótesis a plantear, considerando un 95% de confianza, es la siguiente.
- \(p_X:\) proporción de hombres para los cuales le medicamento presentó eficacia.
- \(p_Y:\) proporción de mujeres para los cuales le medicamento presentó eficacia.
El comando en R para probar está hipótesis es:
prop.test(
x = c(20,50), # Vector que contenga las frecuencias de los éxitos
n = c(140,160), # Vector que contenga los totales por grupo
alternative = "two.sided", # Tipo de hipótesis alternativa
conf.level = 0.95, # Confianza
correct = F # T en caso de que el número de éxitos o fracasos sea menor a 5 (Corrección de Yates)
)##
## 2-sample test for equality of proportions without continuity correction
##
## data: c(20, 50) out of c(140, 160)
## X-squared = 12.012, df = 1, p-value = 0.0005286
## alternative hypothesis: two.sided
## 95 percent confidence interval:
## -0.26193633 -0.07734938
## sample estimates:
## prop 1 prop 2
## 0.1428571 0.3125000Como se observa en la última línea de la salida del programa, la proporción de eficacia del fármaco en los hombres es del 14.28% y del 31.25% en las mujeres.
Al observar el valor-p (0.0005286), nos damos cuenta de que este es menor a la significancia (0.05). Además, el valor de \(\delta_0 = 0\) no está contenido por intervalo de confianza (-0.26193633, -0.07734938), por lo que, existe suficiente evidencia estadística para rechazar \(H_0\), es decir, existe suficiente evidencia estadística apoyar la afirmación de que existe diferencia entre hombres y mujeres respecto a la eficacia del fármaco.
Ejercicio 3.21 Suponga que se quiere comparar la proporción de hogares que tienen una cuenta bancaria en dos países, A y B. En el país A, de una muestra aleatoria de 500 hogares, 400 tienen una cuenta bancaria, mientras que en el país B, de una muestra aleatoria de 800 hogares, 600 tienen una cuenta bancaria. Realice un análisis de la diferencia de proporciones, y determine si hay evidencia de que la proporción de hogares con cuenta bancaria es significativamente diferente entre los dos países.
Ejercicio 3.22 Suponga que se quiere comparar la proporción de empresas que ofrecen seguro de salud a sus empleados entre dos sectores económicos, manufactura y servicios. En el sector manufacturero, de una muestra aleatoria de 300 empresas, 225 ofrecen seguro de salud a sus empleados, mientras que en el sector de servicios, de una muestra aleatoria de 400 empresas, 300 ofrecen seguro de salud a sus empleados. Realice un análisis de la diferencia de proporciones, y determine si hay evidencia de que la proporción de empresas que ofrecen seguro de salud es significativamente diferente entre los dos sectores.
Ejercicio 3.23 Suponga que se quiere comparar la proporción de trabajadores con contratos temporales entre dos empresas, A y B. En la empresa A, de una muestra aleatoria de 400 trabajadores, 120 tienen contratos temporales, mientras que en la empresa B, de una muestra aleatoria de 500 trabajadores, 150 tienen contratos temporales. Realice un análisis de la diferencia de proporciones, y determine si hay evidencia de que la proporción de trabajadores con contratos temporales es significativamente mayor en la empresa A.
Ejercicio 3.24 Suponga que se quiere comparar la proporción de clientes que compran un producto en dos tiendas, A y B. En la tienda A, de una muestra aleatoria de 600 clientes, 200 compran el producto, mientras que en la tienda B, de una muestra aleatoria de 800 clientes, 240 compran el producto. Realiza un análisis de la diferencia de proporciones, y determina si hay evidencia de que la proporción de clientes que compran el producto es significativamente menor en la tienda A.
Ejercicio 3.25 Un estudio analizó la cantidad de personas que reciclan y, que a su vez, hacen uso de un servicio privado o público para la recolección de basura (incluye la recolección de reciclaje). Los datos registrados se reflejan en la siguiente tabla.
| Reciclan | No reciclan | |
|---|---|---|
| Servicio privado | 128 | 234 |
| Servicio público | 340 | 260 |
Plantee una prueba de hipótesis para estudiar si, la proporción de personas que reciclan qué usan el servicio público es menor a la proporción de personas que no reciclan qué uso del mismo tipo de servicio. Utilice una confianza del 97.9%. Concluya utilizando el método del valor-p.
Ejercicio 3.26 La Encuesta de Caracterización Socioeconómica Nacional, Casen, es realizada por el Ministerio de Desarrollo Social y Familia con el objetivo de disponer de información que permita:
Conocer periódicamente la situación de los hogares y de la población, especialmente de aquella en situación de pobreza y de aquellos grupos definidos como prioritarios por la política social, con relación a aspectos demográficos, de educación, salud, vivienda, trabajo e ingresos. En particular, estimar la magnitud de la pobreza y la distribución del ingreso; identificar carencias y demandas de la población en las áreas señaladas; y evaluar las distintas brechas que separan a los diferentes segmentos sociales y ámbitos territoriales.
Evaluar el impacto de la política social: estimar la cobertura, la focalización y la distribución del gasto fiscal de los principales programas sociales de alcance nacional entre los hogares, según su nivel de ingreso, para evaluar el impacto de este gasto en el ingreso de los hogares y en la distribución del mismo. Su objeto de estudio son los hogares que habitan las viviendas particulares ocupadas que se ubican en el territorio nacional, exceptuando algunas comunas y partes de comunas definidas por el INE como áreas especiales, así como las personas que forman parte de esos hogares.
La siguiente tabla, da cuenta de la cantidad de hombres y mujeres (jefes de familia) según su nivel educacional, de una muestra determinada.
| Hombres | Mujeres | |
|---|---|---|
| Universitario completo | 220 | 3201 |
| Escolar completo | 7141 | 4789 |
| Otro nivel educacional | 4593 | 3450 |
Plantee una prueba de hipótesis para estudiar si, la proporción de mujeres que tienen un nivel educacional distinto al de Escolar Completo, es no mayor igual a la proporción de Hombres que tienen un nivel educacional Escolar Completo. Utilice una confianza del 97.1%. Concluya utilizando el método del intervalo de confianza.
Ejercicio 3.27 Se realizó un estudio con el fin de registrar la cantidad de personas morosas respecto al pago de contribuciones, y si estas tienen o no una enfermedad crónica asociada. Las frecuencias se aprecian en la siguiente tabla.
| Moroso | No Moroso | |
|---|---|---|
| Con enfermedad | 128 | 234 |
| Sin enfermedad | 340 | 260 |
A continuación.
Plantee una prueba de hipótesis para estudiar si, las proporciones de personas morosas y no morosas que tienen una enfermedad son distintas. Utilice una confianza del 79.7%. Concluya utilizando el método del valor - p.
Plantee una prueba de hipótesis para estudiar si, la proporción de personas con enfermedad que son morosas es no menor igual a la proporción de personas sin enfermedad que son morosas por menos de 0.2 unidades. Utilice una confianza del 91.2%. Concluya utilizando el método del intervalo de confianza.
3.6 Ejercicios
A continuación, desarrolle los ejercicios manualmente sin el uso de R, a menos que se indique lo contrario.
Ejercicio 3.28 Un encargado de operaciones analiza el tiempo de carga de una aplicación móvil (segundos); se sabe que la desviación estándar poblacional es \(\sigma=2.0\). En una prueba piloto se recolectaron los tiempos de carga de 10 sesiones de uso: 18, 20, 19, 21, 17, 22, 20, 19, 18, 21. Con un nivel de significancia de 5% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para evaluar si el promedio poblacional es distinto de 20. Considere que \(Z_{1-0.05/2}=1.9599\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.29 Un equipo de calidad controla el tiempo de respuesta (ms) de un servicio web; se conoce \(\sigma=10\). Durante un día se tomaron registros de respuesta en 10 solicitudes consecutivas: 205, 199, 201, 208, 202, 207, 203, 200, 204, 206. Con un nivel de significancia del 10% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para estudiar si el promedio poblacional es mayor a 200. Considere que \(Z_{1-0.10}=1.2816\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.30 Un laboratorio registra la acidez de una bebida gaseosa (pH); se conoce \(\sigma=0.20\). En una inspección de calidad se midieron ocho lotes de producción con valores de pH: 3.42, 3.39, 3.41, 3.40, 3.38, 3.43, 3.37, 3.41. Con un nivel de significancia del 5% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para verificar si el pH promedio poblacional es menor a 3.40. Considere que \(Z_{1-0.05}=1.6449, Z_{0.05}=-1.6449\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.31 Una clínica mide la duración de consultas médicas (minutos); las varianzas poblacionales son desconocidas. En un día laboral se registraron las siguientes duraciones de atención en 8 pacientes: 12, 11, 13, 10, 12, 14, 11, 13. Con un nivel de significancia del 1% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para evaluar si el promedio poblacional es distinto de 12. Considere que \(t_{1-0.01/2,\,7}=3.4995\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.32 Un analista de recursos humanos estudia las horas de capacitación recibidas por empleado en una semana; las varianzas poblacionales son desconocidas. Se recopilaron datos de 8 empleados: 5.0, 5.5, 4.8, 5.3, 5.1, 5.6, 5.2, 5.4. Con un nivel de significancia del 5% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para determinar si el promedio poblacional es mayor a 5.0. Considere que \(t_{1-0.05,\,7}=1.8946\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.33 Un responsable de logística mide el tiempo de picking de pedidos (minutos); las varianzas poblacionales son desconocidas. En un turno se observaron los siguientes tiempos de preparación: 9.1, 8.7, 9.0, 8.8, 9.2, 8.9, 8.6. Con un nivel de significancia del 10% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para evaluar si el promedio poblacional es menor a 9.0. Considere que \(t_{1-0.10,\,6}=1.4400, t_{0.10,\,6}=-1.4400\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.34 Dos procesos industriales (X e Y) producen piezas; se conocen \(\sigma_X=1.5\) y \(\sigma_Y=2.0\). Para el proceso X se tomaron mediciones de resistencia: 52, 55, 54, 53, 56, 55, 54. Para el proceso Y se recolectaron mediciones en seis piezas: 50, 48, 49, 51, 47, 50. Con un nivel de significancia de 10% y asumiendo normalidad, elabore una prueba de hipótesis para estudiar si la diferencia de medias poblacionales es distinta de 0. Considere que \(Z_{1-0.10/2}=1.6449\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.35 Dos líneas de ensamblaje (L1 y L2) tienen tiempos de armado (min). Se conocen \(\sigma_{L1}=0.9\) y \(\sigma_{L2}=1.1\). En L1 se midieron los tiempos de seis productos: 12.1, 12.4, 11.9, 12.3, 12.0, 12.2. En L2 se midieron los tiempos de seis productos: 11.4, 11.6, 11.5, 11.7, 11.3, 11.6. Con un nivel de significancia del 5% y asumiendo normalidad, elabore una prueba de hipótesis para verificar si la media de L1 supera a la de L2. Considere que \(Z_{1-0.05}=1.6449\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.36 Dos aplicaciones móviles (A y B) registran latencia de carga (ms); se conocen \(\sigma_A=12\) y \(\sigma_B=10\). Para la app A se registraron los tiempos: 210, 205, 198, 202, 207, 200, 203. Para la app B se registraron: 195, 197, 193, 198, 196, 194, 199. Con un nivel de significancia del 5% y asumiendo normalidad, elabore una prueba de hipótesis para evaluar si la media de A es menor que la de B. Considere que \(Z_{1-0.05}=1.6449, Z_{0.05}=-1.6449\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.37 Dos cursos universitarios (Ingeniería y Economía) rinden un test de conocimientos; las varianzas poblacionales son desconocidas pero se asumen iguales. En Ingeniería se obtuvieron puntajes: 72, 74, 75, 73, 76, 71. En Economía se obtuvieron: 68, 70, 69, 67, 71, 68. Con un nivel de significancia del 5% y asumiendo normalidad, elabore una prueba de hipótesis para estudiar si las medias poblacionales son distintas. Considere que \(t_{1-0.05/2,\,10}=2.2281\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.38 Dos plantas de producción (P1 y P2) comparan su productividad (unidades por hora); las varianzas poblacionales son desconocidas pero se asumen iguales. En P1 se registraron productividades: 105, 110, 108, 107, 109, 106. En P2 se registraron: 100, 98, 101, 99, 102, 100. Con un nivel de significancia del 3% y asumiendo normalidad, elabore una prueba de hipótesis para verificar si la media de P1 supera a la de P2. Considere que \(t_{1-0.03,\,10}=2.2281\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.39 Dos equipos de ventas (X e Y) reportan número de contratos logrados en un mes; las varianzas poblacionales son desconocidas pero se asumen iguales. Para X se recolectaron datos de 7 agentes: 15, 18, 16, 17, 19, 20, 18. Para Y se recolectaron datos de 7 agentes: 12, 14, 13, 15, 14, 13, 12. Con un nivel de significancia del 10% y asumiendo normalidad, elabore una prueba de hipótesis para evaluar si la media de X es menor que la de Y. Considere que \(t_{1-0.10,\,12}=1.3562, t_{0.10,\,12}=-1.3562\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.40 Dos métodos de cultivo agrícola (X e Y) son evaluados en rendimiento (kg por parcela); las varianzas poblacionales son desconocidas y no se asumen iguales. Para X se registraron: 210, 215, 212, 218, 214. Para Y se registraron: 200, 205, 202, 199, 203. Con un nivel de significancia del 5% y asumiendo normalidad, elabore una prueba de hipótesis para estudiar si las medias poblacionales son distintas. Considere que \(t_{1-0.05/2,\,8}=2.3060\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.41 Dos programas de entrenamiento físico (M1 y M2) se comparan por reducción de tiempo en pruebas (s); las varianzas poblacionales son desconocidas y no se asumen iguales. En M1 se registraron mejoras: 62, 65, 63, 64, 66. En M2 se registraron: 58, 57, 59, 56, 60. Con un nivel de significancia del 3% y asumiendo normalidad, elabore una prueba de hipótesis para verificar si la media de M1 supera a la de M2. Considere que \(t_{1-0.03,\,7}=2.3650\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.42 Dos grupos de voluntarios (Control y Experimental) registran tiempo de reacción (ms); las varianzas poblacionales son desconocidas y no se asumen iguales. En el grupo Control se midieron tiempos: 220, 225, 218, 222, 219. En el grupo Experimental se midieron: 210, 212, 208, 211, 209. Con un nivel de significancia del 8% y asumiendo normalidad, elabore una prueba de hipótesis para evaluar si la media del grupo Control es menor que la del grupo Experimental. Considere que \(t_{1-0.08,\,8}=1.8595, t_{0.08,\,8}=-1.8595\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.43 Dos modelos de batería (A y B) son comparados en tiempo de carga (min). Para el modelo A se midieron cargas: 120, 118, 122, 121, 119, 123. Para el modelo B se midieron: 115, 116, 117, 114, 115, 118. Con un nivel de significancia del 5% y asumiendo normalidad, elabore una prueba de hipótesis para estudiar si las varianzas poblacionales son distintas. Considere que \(F_{1-0.05/2,\,5,\,5}=5.05, F_{0.05/2,\,5,\,5}=0.20\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.44 Dos proveedores de insumos (X e Y) registran tiempos de entrega (días). En el proveedor X se observaron: 32, 34, 33, 35, 31, 36. En el proveedor Y se observaron: 28, 29, 30, 27, 31, 29. Con un nivel de significancia del 10% y asumiendo normalidad, elabore una prueba de hipótesis para verificar si la varianza de X es mayor que la de Y. Considere que \(F_{1-0.10,\,5,\,5}=3.33, F_{0.10,\,5,\,5}=0.30\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.45 Dos equipos de producción (E1 y E2) reportan tiempos de set-up (min). En E1 se midieron duraciones: 15, 17, 16, 14, 18, 15. En E2 se midieron: 16, 16, 15, 17, 16, 18. Con un nivel de significancia del 5% y asumiendo normalidad, elabore una prueba de hipótesis para evaluar si la varianza de E1 es menor que la de E2. Considere que \(F_{1-0.05,\,5,\,5}=5.05, F_{0.05,\,5,\,5}=0.20\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.46 En una encuesta de mercado, 100 personas fueron consultadas sobre producto X y 60 declararon preferirlo, mientras que en otra encuesta a 120 personas sobre producto Y, 78 lo prefirieron. Con un nivel de significancia del 5% elabore una prueba de hipótesis para evaluar si la diferencia de proporciones poblacionales es distinta de 0. Considere que \(Z_{1-0.05/2}=1.9599\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.47 En una campaña publicitaria, 150 clientes fueron encuestados y 90 eligieron la versión nueva, mientras que en otro grupo de 160 clientes 70 eligieron la versión antigua. Con un nivel de significancia del 5% elabore una prueba de hipótesis para verificar si la proporción de la versión nueva es mayor que la de la versión antigua. Considere que \(Z_{1-0.05}=1.6449\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.48 En dos regiones se midió la adopción de un programa social. En la Región Norte 52 de 110 personas encuestadas declararon participar, mientras que en la Región Sur 70 de 130 manifestaron lo mismo. Con un nivel de significancia del 10% elabore una prueba de hipótesis para evaluar si la proporción de la Región Norte es menor que la de la Región Sur. Considere que \(Z_{1-0.10}=1.2816, Z_{0.10}=-1.2816\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.49 Un analista de procesos evalúa el tiempo de arranque de servidores (segundos) tras una actualización nocturna; se conoce \(\sigma=3.0\). Durante una ventana de mantenimiento del viernes se registraron 10 arranques consecutivos del mismo clúster: 42, 41, 39, 44, 40, 43, 42, 41, 40, 44. Con un nivel de significancia del 5% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para evaluar si el promedio poblacional es distinto de 41. Considere que \(Z_{1-0.05/2}=1.9599\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.50 Un laboratorio de control mide el contenido de cafeína (mg) de una bebida energética; se conoce \(\sigma=6\). En una corrida de producción del turno mañana se muestrearon 10 latas al azar de la línea de envasado: 83, 86, 90, 85, 88, 84, 87, 89, 86, 85. Con un nivel de significancia del 10% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para verificar si el promedio poblacional es mayor a 85. Considere que \(Z_{1-0.10}=1.2816\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.51 Un área de calidad registra el porcentaje de humedad (puntos porcentuales) de paquetes sellados; se conoce \(\sigma=0.7\). En una ronda de muestreo al final del día se extrajeron 8 paquetes de diferentes estanterías del depósito: 7.1, 6.9, 7.0, 6.8, 7.2, 6.7, 7.0, 6.9. Con un nivel de significancia del 1% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para evaluar si el promedio poblacional es menor a 7.0. Considere que \(Z_{1-0.01}=2.3263, Z_{0.01}=-2.3263\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.52 Una clínica odontológica registra la duración de limpiezas (minutos) en pacientes adultos; las varianzas poblacionales son desconocidas. En un bloque de atención de media mañana se midieron 9 procedimientos consecutivos realizados por el mismo profesional: 32, 35, 31, 33, 34, 30, 32, 33, 31. Con un nivel de significancia del 5% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para evaluar si el promedio poblacional es distinto de 32. Considere que \(t_{1-0.05/2,\,8}=2.3060\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.53 Un departamento de TI registra horas de capacitación semanal por persona en modalidad e-learning; las varianzas poblacionales son desconocidas. Se levantaron datos al cierre del mes para 7 colaboradores seleccionados aleatoriamente: 6.0, 5.8, 6.1, 6.3, 6.2, 5.9, 6.4. Con un nivel de significancia del 10% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para verificar si el promedio poblacional es mayor a 6.0. Considere que \(t_{1-0.10,\,6}=1.4400\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.54 Una bodega controla el tiempo de picking (min) en pedidos minoristas; las varianzas poblacionales son desconocidas. En un turno corto de alta demanda se observaron 8 pedidos seleccionados sistemáticamente cada 5 órdenes: 7.9, 8.1, 8.0, 7.8, 8.2, 7.7, 7.9, 8.0. Con un nivel de significancia del 5% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para evaluar si el promedio poblacional es menor a 8.0. Considere que \(t_{1-0.05,\,7}=1.8946, t_{0.05,\,7}=-1.8946\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.55 Dos líneas de producción (X e Y) se comparan en diámetro de ejes (mm); se conocen \(\sigma_X=0.12\) y \(\sigma_Y=0.10\). En la auditoría de control se tomaron 6 mediciones de ejes consecutivos de X: 10.04, 10.02, 10.01, 10.05, 10.03, 10.04, y 6 mediciones de Y en el mismo turno: 9.98, 10.00, 9.99, 9.97, 10.00, 9.98. Con un nivel de significancia del 5% y asumiendo normalidad, elabore una prueba de hipótesis para estudiar si la diferencia de medias poblacionales es distinta de 0. Considere que \(Z_{1-0.05/2}=1.9599\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.56 Dos turnos (mañana y tarde) se comparan en tiempo de armado (min); se conocen \(\sigma_M=1.0\) y \(\sigma_T=1.2\). En una semana de observación se cronometraron 6 productos por turno, mañana: 14.2, 14.1, 13.9, 14.0, 14.3, 14.1, y tarde: 13.6, 13.7, 13.8, 13.6, 13.9, 13.7. Con un nivel de significancia del 10% y asumiendo normalidad, elabore una prueba de hipótesis para verificar si la media del turno mañana es mayor que la del turno tarde. Considere que \(Z_{1-0.10}=1.2816\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.57 Dos sensores (A y B) miden temperatura ambiental (°C) en salas contiguas; se conocen \(\sigma_A=0.6\) y \(\sigma_B=0.6\). Se tomaron 5 lecturas alternadas por sensor durante la misma franja horaria, A: 22.1, 22.0, 22.3, 22.2, 22.1, B: 22.4, 22.5, 22.6, 22.3, 22.5. Con un nivel de significancia del 5% y asumiendo normalidad, elabore una prueba de hipótesis para evaluar si la media de A es menor que la de B. Considere que \(Z_{1-0.05}=1.6449, Z_{0.05}=-1.6449\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.58 Dos talleres (T1 y T2) comparan puntajes de una prueba técnica estandarizada; las varianzas poblacionales son desconocidas pero se asumen iguales. En la misma semana, T1 aplicó la prueba a 6 estudiantes (78, 80, 79, 81, 77, 80) y T2 a otros 6 (74, 76, 75, 77, 76, 75). Con un nivel de significancia del 5% y asumiendo normalidad, elabore una prueba de hipótesis para estudiar si las medias poblacionales son distintas. Considere que \(t_{1-0.05/2,\,10}=2.2281\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.59 Dos plantas (P1 y P2) evalúan rendimiento (unid/h); las varianzas poblacionales son desconocidas pero se asumen iguales. En un ciclo homogéneo de producción se registraron 6 horas por planta, P1: 92, 95, 93, 94, 96, 95, P2: 90, 89, 91, 90, 92, 91. Con un nivel de significancia del 1% y asumiendo normalidad, elabore una prueba de hipótesis para verificar si la media de P1 supera a la de P2. Considere que \(t_{1-0.01,\,10}=2.7638\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.60 Dos equipos (E1 y E2) comparan ventas diarias (miles) en sucursales equivalentes; las varianzas poblacionales son desconocidas pero se asumen iguales. Durante una semana comparativa se registraron 6 días por equipo, E1: 18, 19, 17, 20, 18, 19, E2: 19, 18, 20, 19, 21, 20. Con un nivel de significancia del 10% y asumiendo normalidad, elabore una prueba de hipótesis para evaluar si la media de E1 es menor que la de E2. Considere que \(t_{1-0.10,\,10}=1.3722, t_{0.10,\,10}=-1.3722\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.61 Dos métodos de estudio (X e Y) se comparan en puntaje final de un módulo online; las varianzas poblacionales son desconocidas y no se asumen iguales. Con una muestra al cierre del módulo se obtuvieron X: 5.8, 6.0, 6.1, 5.9, 6.2 y Y: 5.5, 5.6, 5.7, 5.5, 5.8. Con un nivel de significancia del 5% y asumiendo normalidad, elabore una prueba de hipótesis para estudiar si las medias poblacionales son distintas. Considere que \(t_{1-0.05/2,\,8}=2.3060\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.62 Dos tratamientos (A y B) se comparan en reducción de colesterol (mg/dL) en pacientes con perfil similar; las varianzas poblacionales son desconocidas y no se asumen iguales. En un ensayo piloto se observaron A: 18, 22, 20, 21, 19 y B: 14, 15, 16, 13, 15. Con un nivel de significancia del 3% y asumiendo normalidad, elabore una prueba de hipótesis para verificar si la media de A supera a la de B. Considere que \(t_{1-0.03,\,7}=2.3650\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.63 Dos grupos (Control e Intervención) miden tiempo de completar una tarea (s) en laboratorio; las varianzas poblacionales son desconocidas y no se asumen iguales. En una sesión doble se midieron Control: 48, 47, 49, 46, 48 e Intervención: 47, 46, 45, 47, 46. Con un nivel de significancia del 10% y asumiendo normalidad, elabore una prueba de hipótesis para evaluar si la media del grupo Control es menor que la del grupo Intervención. Considere que \(t_{1-0.10,\,8}=1.8595, t_{0.10,\,8}=-1.8595\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.64 Dos líneas de producto (L1 y L2) comparan la variabilidad en peso de empaques (g). Para una inspección rutinaria se tomaron 6 unidades de cada línea, L1: 101, 102, 100, 103, 101, 102 y L2: 99, 100, 100, 98, 99, 100. Con un nivel de significancia del 5% y asumiendo normalidad, elabore una prueba de hipótesis para estudiar si las varianzas poblacionales son distintas. Considere que \(F_{1-0.05/2,\,5,\,5}=5.05, F_{0.05/2,\,5,\,5}=0.20\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.65 Dos proveedores (A y B) comparan la variabilidad del tiempo de despacho (horas) en rutas urbanas. Se monitorearon 6 despachos por proveedor en la misma franja horaria, A: 11, 12, 10, 11, 12, 11 y B: 9, 9, 10, 8, 9, 10. Con un nivel de significancia del 1% y asumiendo normalidad, elabore una prueba de hipótesis para verificar si la varianza de A es mayor que la de B. Considere que \(F_{1-0.01,\,5,\,5}=10.97\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.66 Dos laboratorios (L1 y L2) evalúan la variabilidad en concentración (ppm) del mismo reactivo. Se tomaron 6 réplicas independientes en cada laboratorio durante el mismo día, L1: 50.1, 50.3, 50.2, 50.0, 50.2, 50.1 y L2: 50.4, 50.5, 50.3, 50.6, 50.4, 50.5. Con un nivel de significancia del 10% y asumiendo normalidad, elabore una prueba de hipótesis para evaluar si la varianza de L1 es menor que la de L2. Considere que \(F_{1-0.10,\,5,\,5}=3.33, F_{0.10,\,5,\,5}=0.30\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.67 En dos ciudades se midió la preferencia por un sistema de transporte mediante encuestas presenciales. En Ciudad Norte respondieron 72 de 140 a favor y en Ciudad Sur 60 de 120 a favor. Con un nivel de significancia del 5% elabore una prueba de hipótesis para evaluar si las proporciones poblacionales son distintas. Considere que \(Z_{1-0.05/2}=1.9599\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.68 En una prueba A/B de una aplicación móvil, 84 de 200 usuarios con la versión nueva completaron la compra y 70 de 210 con la versión antigua lo hicieron durante la misma semana de campaña. Con un nivel de significancia del 10% elabore una prueba de hipótesis para verificar si la proporción de la versión nueva es mayor que la de la versión antigua. Considere que \(Z_{1-0.10}=1.2816\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.69 En dos zonas de venta se midió conversión a compra con el mismo script comercial. Zona Este: 45 de 90 casos con conversión, Zona Oeste: 58 de 125 casos con conversión. Con un nivel de significancia del 5% elabore una prueba de hipótesis para evaluar si la proporción de la Zona Este es menor que la de la Zona Oeste. Considere que \(Z_{1-0.05}=1.6449, Z_{0.05}=-1.6449\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.70 Un responsable de manufactura mide tiempos de cambio de formato (min) en una línea automatizada; se conoce \(\sigma=2.5\). En una semana de pruebas se observaron 10 cambios seleccionados aleatoriamente entre turnos: 19, 18, 20, 22, 17, 21, 20, 19, 18, 21. Con un nivel de significancia del 3% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para evaluar si el promedio poblacional es distinto de 20. Considere que \(Z_{1-0.03/2}=2.1701\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.
Ejercicio 3.71 Un control de calidad mide la dureza (HRC) de piezas templadas; se conoce \(\sigma=1.8\). En una inspección al azar se registraron 8 piezas consecutivas de la misma cuba: 58.1, 57.9, 58.4, 58.2, 58.0, 58.3, 58.1, 58.2. Con un nivel de significancia del 5% y asumiendo normalidad de los datos, elabore una prueba de hipótesis para verificar si el promedio poblacional es mayor a 58.0. Considere que \(Z_{1-0.05}=1.6449\). El valor-p debe calcularse en R. Utilice todos los métodos de rechazo.